web crawling
-
웹 크롤러(자동화 Bot) -> 일정한 규칙으로 웹 페이지 브라우징
web scraping
-
웹 사이트에서 원하는 정보를 추출
**다이어그램 그릴 때
Flowchart Maker & Online Diagram Software
Flowchart Maker and Online Diagram Software diagrams.net (formerly draw.io) is free online diagram software. You can use it as a flowchart maker, network diagram software, to create UML online, as an ER diagram tool, to design database schema, to build BPM
app.diagrams.net
**Selenium
-
웹 애플리케이션 테스트 프레임워크
-
웸 사이트에서 버튼 클릭과 같이 이벤트 처리 가능
-
JavaScript 실행 가능
-
웹 브라우저 실행을 대신하기 위한 Web Driver 설치 -> Selenium이 사용하기 위한 웹 브라우저
- http://chromedriver.chromium.org/downloads
Downloads - ChromeDriver - WebDriver for Chrome
WebDriver for Chrome
chromedriver.chromium.org
-
$pip install selenium
-
input 태그에 name이나 id같은 선택자가 있으면 selenium에서 테스트가능
cmd, powerShell, bash shell
conda --version
conda list
conda info --envs(가상환경정보)
conda create --name myselenium(가상환경 만들기)
conda remove --name pandas_venv --all(가상환경 지우기)
conda activate myselenium(활성화)
conda deactivate(비활성화)
conda list
conda install selenium (pip install selenium)
#selenium_test.py(구글)
from selenium import webdriver
path = "/Users/mhee4/cloud/webdriver/chromedriver"
driver = webdriver.Chrome(path)
driver.get("https://www.google.com")
print(driver.title)
search_box = driver.find_element_by_name("q")
search_box.send_keys("아마존 웹 서비스")
search_box.submit()
#selenium_test2.py(페이스북)
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
path = "/Users/mhee4/cloud/webdriver/chromedriver"
driver = webdriver.Chrome(path)
driver.get("https://www.facebook.com")
print(driver.title)
elem_email = driver.find_element_by_id("email")
elem_email.send_keys("[페이스북 아이디]")
elem_pass = driver.find_element_by_id("pass")
elem_pass.send_keys("[페이스북 비밀번호]")
elem_pass.send_keys(Keys.RETURN)
profile_a = driver.find_element_by_xpath('//*[@id="mount_0_0"]/div/div[1]/div[1]/div[3]/div/div/div[1]/div[1]/div/div[1]/div/div/div[1]/div/div/div[1]/ul/li/div/a')
print("Profile A =>", profile_a.get_attribute('href'))
friends_a = driver.find_element_by_xpath('//*[@id="mount_0_0"]/div/div[1]/div[1]/div[3]/div/div/div[1]/div[1]/div/div[1]/div/div/div[1]/div/div/div[1]/div[1]/ul/li[2]/div/a')
print("friends A =>", friends_a.get_attribute('href'))
driver.get(profile_a.get_attribute('href'))
# driver.get(friends_a.get_attribute('href'))
#selenium_test3.py(깃헙)
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
path = "/Users/mhee4/cloud/webdriver/chromedriver"
driver = webdriver.Chrome(path)
driver.get("https://www.github.com/login")
print(driver.title)
elem_email = driver.find_element_by_id("login_field")
elem_email.send_keys("[깃헙 아이디]"])
elem_pass = driver.find_element_by_id("password")
elem_pass.send_keys("[깃헙 비밀번호]")
elem_pass.send_keys(Keys.RETURN)
**깃헙에 push 잘못했을 때 예전 기록으로 돌아가는 법
[꿀팁] Github에 이미 push 해버린 commit 지우기
개요 Github에 이미 push를 해버렸는데 commit이 의미 없어져 지워야 할일이 생겼다. 개인 repo라면 귀찮더라도 repo를 삭제하고 다시만들수도 있겠지만 이 또한 비효율적이고 수고스럽다. 따라서 이미
www.kwangsiklee.com
$git reset [돌아가고싶은 로그번호] --hard
$git push origin -f
**Scrapy
-
수많은 웹 페이지로부터 정보를 수집 -> 빅데이터로 활용
-
Scrapying을 위한 라이브러리
-
$pip install scrapy
-
Scrapy Shell
-
$scrapy shell
https://news.naver.com/main/list.nhn?mode=LS2D&sid2=230&sid1=105&mid=shm&date=20210119&page=1
https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid2=230&sid1=105&date=20210119&page=2
https://news.naver.com/main/list.nhn?mode=LS2D&sid2=230&sid1=105&mid=shm&date=20210119&page=3
client(web browser)
-> server(요청)
->주소(리소스의 위치): https://news.naver.com/main/list.nhn
->전달 파라미터: mode=LS2D&
sid2=230&
sid1=105&
mid=shm&
date=20210119&
page=3
(key) = (value)
여러개 파라미터 전달 시 구분 기호 : &
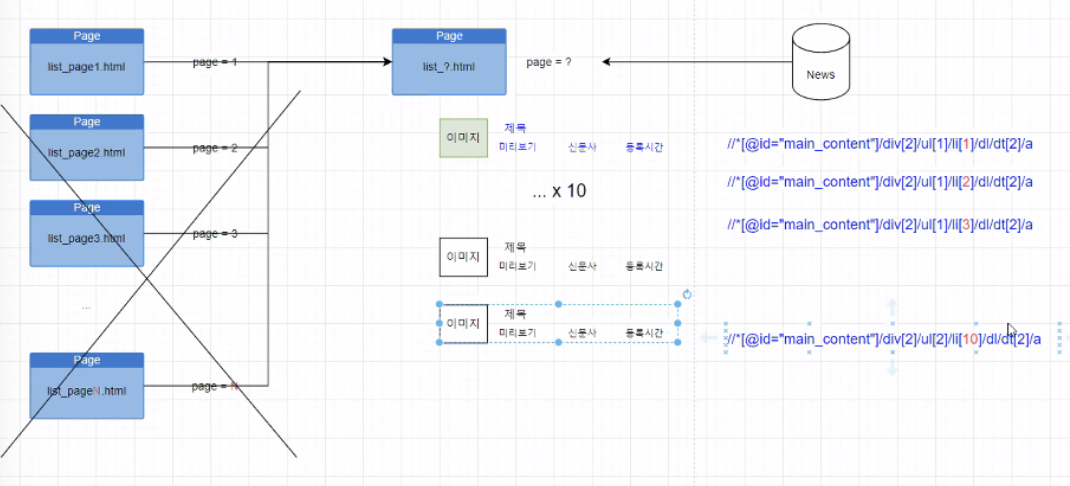
//*[@id="main_content"]/div[2]/ul[1]/li[1]/dl/dt[2]/a
//*[@id="main_content"]/div[2]/ul[1]/li[2]/dl/dt[2]/a
//*[@id="main_content"]/div[2]/ul[1]/li[3]/dl/dt[2]/a
//*[@id="main_content"]/div[2]/ul[2]/li[10]/dl/dt[2]/a
//*[@id="main_content"]/div[2]/ul[1]/li[1]/dl/dt[2]/a(두번째 페이지)
-
크롤링 타겟
-
제목
-
올린 뉴스 사이트
-
미리보기 내용
-
XPath를 가지고 크롤링
$scrapy shell
>>>fetch('https://news.naver.com/main/read.nhn?mode=LSD&mid=shm&sid1=101&oid=215&aid=0000930614')
>>>view(response)
>>>print(response.text)
>>>response.xpath('//*[@id="main_content"]/div[2]/ul/li/dl/dt[2]/a/text()').extract()
>>>response.css('.writing::text').extract()
>>>response.css('.lede::text').extract()
$scrapy startproject myscraper
$cd myscraper
$code .
$scrapy genspider mybots "news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=105&sid2=230"
#items.py
import scrapy
class MyscraperItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
writer = scrapy.Field()
preview = scrapy.Field()#spiders/mybots.py
import scrapy
from myscraper.items import MyscraperItem
class MybotsSpider(scrapy.Spider):
name = 'mybots'
allowed_domains = ['naver.com']
start_urls = ['http://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=105&sid2=230/']
def parse(self, response):
titles = response.xpath('//*[@id="main_content"]/div[2]/ul/li/dl/dt[2]/a/text()').extract()
writers = response.css('.writing::text').extract()
previews = response.css('.lede::text').extract()
# zip(titles, writers, previews)
items = []
# items에 XPATH, CSS를 통해 추출한 데이터를 저장
for idx in range(len(titles)):
item = MyscraperItem()
item['title'] = titles[idx]
item['writer'] = writers[idx]
item['preview'] = previews[idx]
items.append(item)
return items
#settings.py
ROBOTSTXT_OBEY = False
FEED_FORMAT = "csv"
FEED_URI = "my_news.csv"
FEED_EXPORT_ENCODING = 'utf-8-sig'$scrapy crawl mybots
**네이버 영화 평점(리뷰) 가져오기
-
Scrapy 이용
-
제목, 평점, 내용, 작성자, 날짜
#items.py
class MyScraperItem2(scrapy.Item):
title = scrapy.Field()
grade = scrapy.Field()
content = scrapy.Field()
writer = scrapy.Field()
date = scrapy.Field()
#spiders/mybots.py
import scrapy
from myscraper.items import MyscraperItem, MyScraperItem2
class MybotsSpider(scrapy.Spider):
name = 'mybots'
allowed_domains = ['movie.naver.com']
start_urls = ['https://movie.naver.com/movie/point/af/list.nhn']
def parse(self, response):
titles = response.xpath('//*[@id="old_content"]/table/tbody/tr/td[2]/a[1]/text()').extract()
grades = response.css('.list_netizen_score em::text').extract()
contents = response.css('.title::text').extract()
writers = response.css('.author::text').extract()
dates = response.css('td.num::text').extract()
# zip(titles, writers, previews)
items = []
# items에 XPATH, CSS를 통해 추출한 데이터를 저장
for idx in range(len(titles)):
item = MyScraperItem2()
item['title'] = titles[idx]
item['grade'] = grades[idx]
item['content'] = contents[idx]
item['writer'] = writers[idx]
item['date'] = dates[idx]
items.append(item)
return items
---->강사님 코드
$scrapy startproject myscraper
$cd myscraper
$code .
$scrapy genspider [봇 이름] "news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=105&sid2=230"
$scrapy crawl [봇 이름]
$conda info --envs
$conda create --name mymovie
$conda activate mymovie
$conda list
$conda install scrapy
$code test.txt(없으면 새로 만들어줌)
$code .(현재 디렉토리 통째로 오픈)
scrapy shell
->확인
#items.py
import scrapy
# Model (DB와 연관되는 데이터(객체))
class MymovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
star = scrapy.Field()
desc = scrapy.Field()
writer = scrapy.Field()
date = scrapy.Field()
#spiders/mymovie_bots.py
import scrapy
from mymovie.items import MymovieItem
# descs -> 40개의 데이터(공백포함) -> 10데이터(공백제거)
def remove_space(descs:list) -> list:
result = []
for i in range(len(descs)):
if len(descs[i].strip()) > 0:
result.append(descs[i].strip())
return result
class MymovieBotsSpider(scrapy.Spider):
name = 'mymovie_bots'
allowed_domains = ['naver.com']
start_urls = ['http://movie.naver.com/movie/point/af/list.nhn']
def parse(self, response):
titles = response.xpath('//*[@id="old_content"]/table/tbody/tr/td[2]/a[1]/text()').extract()
stars = response.xpath('//*[@id="old_content"]/table/tbody/tr/td[2]/div/em/text()').extract()
descs = response.css('.title::text').extract()
converted_descs = remove_space(descs)
writers = response.css('.author::text').extract()
dates = response.xpath('//*[@id="old_content"]/table/tbody/tr/td[3]/text()').extract()
items = []
for row in zip(titles, stars, converted_descs, writers, dates):
item = MymovieItem()
item['title'] = row[0]
item['star'] = row[1]
item['desc'] = row[2]
item['writer'] = row[3]
item['date'] = row[4]
yield item # 제너레이터
**yield
순차적인 iterator를 생성해주는 것 = generator
파이썬 제너레이션을 사용할 때 이 값을 반환해준 것 = yield
**여러페이지 크롤링하기
https://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=105&sid2=230
https://news.naver.com/main/list.nhn?mode=LS2D&sid2=230&sid1=105&mid=shm&date=20210119&page=1
https://docs.scrapy.org/en/latest/topics/spiders.html?highlight=scrapy.Spider#scrapy-spider
Spiders — Scrapy 2.4.1 documentation
Spiders Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items). In other words, Spiders are
docs.scrapy.org
#spiders/mybots.py
import scrapy
from myscraper.items import MyscraperItem, MyScraperItem2
from scrapy.http import Request
URL = 'http://news.naver.com/main/list.nhn?mode=LS2D&mid=shm&sid1=105&sid2=230&page=%s'
start_page = 1
# print(URL % start_page)
# print(URL.format(start_page))
class MybotsSpider(scrapy.Spider):
name = 'mybots'
allowed_domains = ['naver.com']
start_urls = [URL % start_page]
def start_requests(self):
for i in range(2): # 0, 1
yield Request(url=URL % (i + start_page), callback=self.parse)
def parse(self, response):
titles = response.xpath('//*[@id="main_content"]/div[2]/ul/li/dl/dt[2]/a/text()').extract()
writers = response.css('.writing::text').extract()
previews = response.css('.lede::text').extract()
# zip(titles, writers, previews)
items = []
# items에 XPATH, CSS를 통해 추출한 데이터를 저장
for idx in range(len(titles)):
item = MyscraperItem()
item['title'] = titles[idx]
item['writer'] = writers[idx]
item['preview'] = previews[idx]
items.append(item)
return items
'CLOUD > Python' 카테고리의 다른 글
| 1/18 웹스크래핑 - 복습, scrapy (0) | 2021.01.18 |
|---|---|
| 1/11 파이썬 6차시 - 웹스크래핑(MariaDB연동), 시각화 (0) | 2021.01.11 |
| 1/6 파이썬 5차시 - 웹스크래핑(csv, xml, json타입 처리), 데이터 분석 (0) | 2021.01.06 |
| 1/5 파이썬 4차시 - 깃파이참연동, 모듈과 패키지, 예외처리, 파일다루기, 웹스크래핑 (0) | 2021.01.05 |
| 1/4 파이썬 3차시 - 함수가이드라인, pythonic code, 람다, 객체와클래스, 모듈과 패키지 (0) | 2021.01.04 |