**yesterday과제
# mode -r(read), w(write), a(append), rb(read binary), wb(write binary)
myFile = open('yesterday.txt', 'r')
yesterday_lyric = myFile.read()
myFile.close()with open('yesterday.txt','r') as f:
yesterday_lyric = f.read()->with구문으로 간단하게 사용할 수 있다.
# file read 를 함수로 선언
def file_read(file_name):
with open(file_name, 'r') as f:
lyric = f.read()
print(lyric)
return lyric
# 함수 호출
yesterday_lyric = file_read('yesterday.txt')
**list 이어서
# 엘리먼트 삭제
str_list.remove('Cobol')
del str_list[0]
del str_list[:3]
print(str_list * 2)
print('Scalar' in str_list)
print('java' in str_list)>>['python', 'Typescript', 'javascript', 'kotlin', 'c++', 'scalar', 'Cobol']
----------------------
['c++', 'scalar', 'c++', 'scalar']
False
False
num_list = [60, 10, 30, 70, 80]
num_list2 = [1, 2, 3, 4, 5]
# 리스트의 메모리 저장 방식
print(num_list, num_list2)
num_list2 = num_list
print(num_list, num_list2)
num_list.sort()
print(num_list, num_list2)
num_list2 = [1, 2, 3, 4, 5]
num_list.sort()
print(num_list, num_list2)>>>[60, 10, 30, 70, 80] [1, 2, 3, 4, 5]
[60, 10, 30, 70, 80] [60, 10, 30, 70, 80]
[10, 30, 60, 70, 80] [10, 30, 60, 70, 80]
[10, 30, 60, 70, 80] [1, 2, 3, 4, 5]
**리스트로 변환하는 과정
-
list('cat')
-
split('/')
-
index() ->index찾을때
my_list = list('Python') # str -> list
print(type(my_list), my_list)
my_list2 = 'Hello, Python'.split(',') # str -> list
print(my_list2)>>><class 'list'> ['P', 'y', 't', 'h', 'o', 'n']
['Hello', ' Python']
# packing 과 unpacking
# packing
my_list3 = ['aa', 'bb']
# unpacking(수가 일치해야함)
str1, str2 = ['cc', 'dd']
print(str1)
print(str2)>>>cc
dd
# eliment 추가
my_list4 = ['dd', 'ff']
my_list3.extend(my_list4)
print(my_list3)
**연습문제(2차원 배열)
kor_score = [49, 79, 20, 100, 80]
math_score = [43, 59, 85, 30, 90]
eng_score = [49, 79, 48, 60, 100]
midterm_score = [kor_score, math_score, eng_score]
print(midterm_score)
print(midterm_score[0])
print(midterm_score[0][3])
for subject in midterm_score:
print(subject)
for student in subject:
print(student)
--디버그의 역할
🔧한줄한줄 실행했을 때 진행현황을 볼 수 있다. -> break point걸기
step over -> 함수 안으로 들어가지 않음. 전체적인 맥락을 실행순서대로 한줄한줄 볼 수 있음
step into -> open이라는 파이썬이 제공하는 함수에 들어가서 한줄 한줄씩 실행시킴
step into my code -> api나 함수는 step over로 개발자가 만든 함수는 step into로 처리해줌
step out -> 빠져나오기(불필요한 함수를 보고싶지 않을 때)
resume program -> 실행 끝
**디버깅 & 리팩토링 기능 => 파이참이 제공하는 기능
리팩토링 -> 이름을 바꾸면 호출하는 쪽의 이름도 자동으로 변경됨
--제어문
x ==y x != y
x is y x is not y
**연습문제
'''
나이 = 현재년도 - 태어난 년도 +1
태어난 년도를 입력 받음 input()
from 모듈명 import
'''
from datetime import datetime as dt
print('태어난 년도를 입력해주세요.')
a = int(input())
# 현재 년도 datetime 클래스에 선언된 today() 메서드를 호출
age = dt.today().year - a + 1
if 17 <= age < 20:
print('고등학생입니다.')
elif 20 <= age < 27:
print('대학생입니다.')
else:
print('학생이 아닙니다.')>>>태어난 년도를 입력해주세요.
1997
대학생입니다.
**튜플
읽기전용, 속도가 빠름

**제어문 함수
for val in range(1, 10, 2):
print(val)>>>1
3
5
7
9
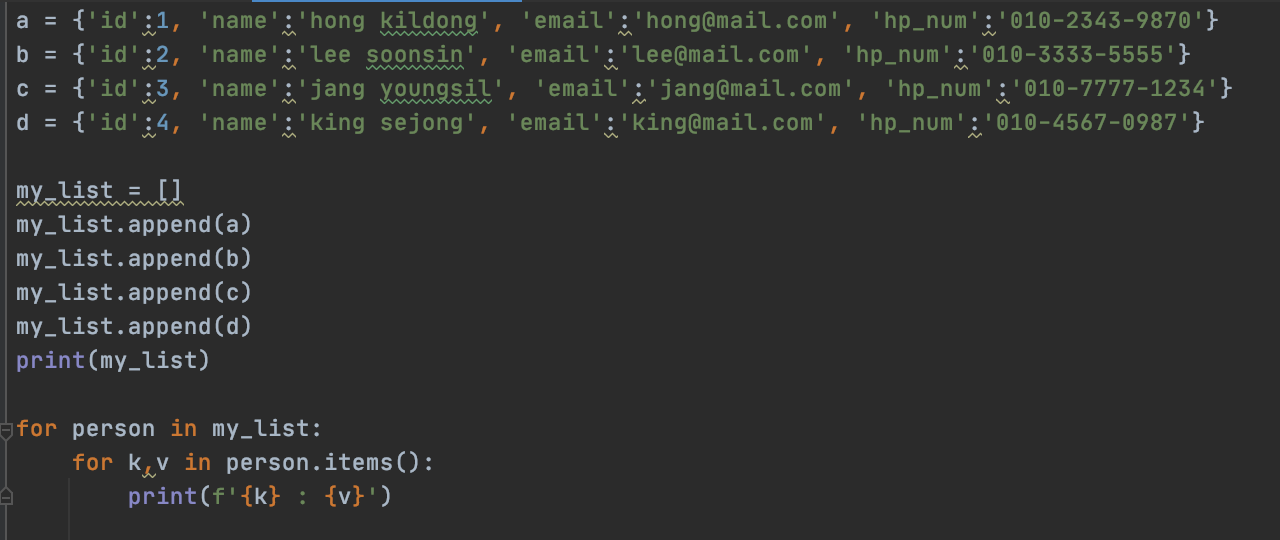
--key & value 함께 가져오는 함수 = items()
# dict 선언
wish_travel_cities = {
'일본' : '도쿄',
'한국' : '서울',
'미국' : '뉴욕',
'한국' : '부산'
}
print(wish_travel_cities['일본'])
print(wish_travel_cities.keys())
print(wish_travel_cities.values())
print(wish_travel_cities.items())
for key in wish_travel_cities.keys():
# pass
print(f'{key} 의 {wish_travel_cities[key]}을(를) 여행하고 싶어요.')
# print(key)
for k, v in wish_travel_cities.items():
# print(k,v)
print(f'{k}의 {v}을/를 방문하고 싶어')>>>도쿄
dict_keys(['일본', '한국', '미국'])
dict_values(['도쿄', '부산', '뉴욕'])
dict_items([('일본', '도쿄'), ('한국', '부산'), ('미국', '뉴욕')])
일본 의 도쿄을(를) 여행하고 싶어요.
한국 의 부산을(를) 여행하고 싶어요.
미국 의 뉴욕을(를) 여행하고 싶어요.
일본의 도쿄을/를 방문하고 싶어
한국의 부산을/를 방문하고 싶어
미국의 뉴욕을/를 방문하고 싶어
import random
for val in range(10):
random_value = random.randint(1, 100)
print(random_value)
print(random.random())
print(random.choice([1, 2, 3, 4, 5]))
print(random.randint(1, 100))>>>80
79
14
55
40
20
55
76
96
83
0.9486320390667808
4
59
for val in range(1, 10, 2):
print(val)
else:
print('for loop 종료')>>>1
3
5
7
9
for loop 종료
# while ~ else
print('while문')
i = 1
while i < 10:
print(i)
i += 2
else:
print('whlie문 종료')>>>while문
1
3
5
7
9
whlie문 종료
**학생별 과목평균 구하기
kor_score = [49, 79, 20, 100, 80]
math_score = [43, 59, 85, 30, 90]
eng_score = [49, 79, 48, 60, 100]
midterm_score = [kor_score, math_score, eng_score]
student_score = [0, 0, 0, 0, 0]
for i in range(3):
for j in range(5):
student_score[j] += midterm_score[i][j]
print(student_score)
else :
for k in range(5):
print(f'평균은 {student_score[k]/3} 입니다.')>>>[141, 217, 153, 190, 270]
평균은 47.0 입니다.
평균은 72.33333333333333 입니다.
평균은 51.0 입니다.
평균은 63.333333333333336 입니다.
평균은 90.0 입니다.
->강사님 버전
student_score = [0, 0, 0, 0, 0]
idx = 0
for subject in midterm_score:
# 학생별 과목합계 점수를 계산
for score in subject:
student_score[idx] += score
idx += 1
# 과목이 바뀔 때 학생 인덱스 초기화
idx = 0
else:
# 평균을 계산(unpacking사용)
print(f'학생별 합계점수 {student_score}')
a, b, c, d, e = student_score
student_average = [int(a/3), int(b/3), int(c/3), int(d/3), int(e/3)]
print(f'학생별 평균점수 = {student_average}')>>>학생별 합계점수 [141, 217, 153, 190, 270]
학생별 평균점수 = [47, 72, 51, 63, 90]
**🔆자료구조🔆
-Data Structure란?
✔️메모리상에서 데이터를 효율적으로 관리하는 방법
✔️검색, 저장 등의 작업에서 효율성을 고려하여 메모리 사용량과 실행시간 등을 최소화 해준다.
✔️파이썬에서 List, Tuple, Set, Dictionary등의 기본 데이터 구조를 제공한다.
✔️스택과 큐
✔️튜플과 집합
✔️사전
**스택(Stack)
-
나중에 넣은 데이터를 먼저 반환되도록 설계된 메모리구조, Last In First Out(LIFO)
-
Data의 입력을 Push, 출력을 Pop이라고 함
-
파이썬은 List를 사용하여 스택 구조를 활용
-
push를 append(), pop은 pop() 사용
**큐(Queue)
-
처음에 넣은 데이터를 먼저 반환되도록 설계된 메모리 구조로 FIFO(First In First Out)
-
Stack과 반대되는 개념
-
파이썬은 LIst를 사용하여 큐 구조를 활용
-
put은 append(), get은 pop(0)을 사용
'''
Stack 과 Queue를 List로 작성한다
'''
stack_list = [1, 2, 3, ]
stack_list.append(5)
stack_list.extend([10,20])
print(stack_list)
# LIFO
stack_list.pop()
print(stack_list)
stack_list.pop()
print(stack_list)
# FIFO
queue_list = [10, 20, 30]
queue_list.pop(0)
print(queue_list)>>>[1, 2, 3, 5, 10, 20]
[1, 2, 3, 5, 10]
[1, 2, 3, 5]
[20, 30]
**튜플(tuple) - read only
-
값의 변경이 불가능한 리스트
-
선언시 "[]" 가 아닌 "()" 를 사용
-
리스트의 연산, 인덱싱, 슬라이싱 등을 동일하게 사용함
**튜플과 리스트
-
튜플은 더 적은 공간을 사용한다.
-
실수로 튜플의 항목이 손상될 염려가 없다.
-
함수의 파라미터들은 튜플로 전달된다.
-
튜플을 사용하는 이유는 프로그램을 작동하는 동안 변경되지 않는 데이터의 저장
-
예) 학번, 이름, 우편번호 등
# tuple = read only list
my_tuple = tuple([10, 30, 40])
my_tuple2 = (20, 30, 40)
print(type(my_tuple), type(my_tuple2))
print(my_tuple[2], my_tuple2[0:2], my_tuple * 2)
# 값 변경은 불가
# my_tuple[1] = 50
# ,의 유무 중요하다
my_int = (10)
my_tuple3 = (10,)
print(type(my_int), type(my_tuple3))>>><class 'tuple'> <class 'tuple'>
40 (20, 30) (10, 30, 40, 10, 30, 40)
<class 'int'> <class 'tuple'>
**집합(Set) - 중복 허용 안함
-
값을 순서 없이 저장, 중복을 허용하지 않는 자료형
-
set 객체 선언을 이용하여 객체 생성
# set - 값의 중복을 허용하지 않는 list
my_set = set([1, 2, 3, 1, 2, 3])
print(type(my_set), my_set)
my_set.add(4)
print(my_set)
my_set.remove(1)
print(my_set)
my_set.update([1, 4, 5, 6, 7])
print(my_set)
my_set.discard(3)
print(my_set)
my_set.clear()
print(my_set)>>><class 'set'> {1, 2, 3}
{1, 2, 3, 4}
{2, 3, 4}
{1, 2, 3, 4, 5, 6, 7}
{1, 2, 4, 5, 6, 7}
set()
s1 = set([1, 2, 3, 4, 5])
s2 = set([3, 4, 5, 6, 7])
print('합집합', s1.union(s2), s1 | s2)
print('교집합', s1.intersection(s2), s1 & s2)
print('차집합', s1.difference(s2), s1 - s2)>>>합집합 {1, 2, 3, 4, 5, 6, 7} {1, 2, 3, 4, 5, 6, 7}
교집합 {3, 4, 5} {3, 4, 5}
차집합 {1, 2} {1, 2}
**Dictionary(딕셔너리, 딕트)
-
리스트와 유사하지만 인덱스 대신에 키를 통해 값을 찾는다.
-
key와 value를 매칭하여 key로 value를 검색한다.
-
다른 언어에서는 hash table, hash map이라는 용어를 사용한다.
# dict 타입
# dict(), {}
lang_dict = {}
lang_dict2 = dict()
print(type(lang_dict), type(lang_dict2))
# dict 값을 저장
lang_dict[100] = '자바'
lang_dict[200] = '파이썬'
lang_dict[200] = '텐서플로'
lang_dict[300] = 'PyTorch'
print(lang_dict)
# dict에서 값을 읽기
print(lang_dict[300])
# KeyError: 400
# print(lang_dict[400])
value = lang_dict.get(400)
print(value)
if value :
print(value)
else :
print('해당 key값이 없음')
for k, v in lang_dict.items():
print(k, v)
del lang_dict>>><class 'dict'> <class 'dict'>
{100: '자바', 200: '텐서플로', 300: 'PyTorch'}
PyTorch
None
해당 key값이 없음
100 자바
200 텐서플로
300 PyTorch
print(200 in lang_dict)
print(400 in lang_dict)
my_dict = {'a' : 100, 'b':200}
print(my_dict['a'])
print('자바' in lang_dict.values())>>>True
False
100
True
**⭐️⭐️zip함수를 이용하여 여러 시퀀스 병렬로 순회하기 (index같은 것끼리 묶어줌)
-
여러 시퀀스 중 가장 짧은 시퀀스가 완료되면 zip()은 멈춘다.
# zip() 함수 -> 이 자체가 iterable 객체
days = ['월요일', '화요일', '수요일']
fruits = ['사과', '바나나', '딸기']
coffees = ['아메리카노', '라떼', '모카', '믹스']
print(zip(days, fruits, coffees), type(zip(days, fruits, coffees)))
for day, fruit, coffee in zip(days, fruits, coffees):
print(day, fruit, coffee)
print(dict(zip(days, fruits)))
print(list(zip(days, fruits)))
for value in list(zip(days, coffees)):
print(value)>>><zip object at 0x7f87c1903d80> <class 'zip'>
월요일 사과 아메리카노
화요일 바나나 라떼
수요일 딸기 모카
{'월요일': '사과', '화요일': '바나나', '수요일': '딸기'}
[('월요일', '사과'), ('화요일', '바나나'), ('수요일', '딸기')]
('월요일', '아메리카노')
('화요일', '라떼')
('수요일', '모카')
days_tuple = '월요일', '화요일', '수요일'
coffees_tuple = '아메리카노', '라떼', '모카'
print(type(days_tuple))
print(list(zip(days_tuple, coffees_tuple)))
print(dict(zip(days_tuple, coffees_tuple)))>>><class 'tuple'>
[('월요일', '아메리카노'), ('화요일', '라떼'), ('수요일', '모카')]
{'월요일': '아메리카노', '화요일': '라떼', '수요일': '모카'}
**zip, range()와 같은 함수는 iterable객체를 반환한다! -> 값 확인을 위해선 for문을 돌리거나 list형식으로 만드렁 줘야 한다.
# zip(), range() 함수는 iterable 객체를 반환하기 때문에 값을 확인하려면 for ~ in을 쓰거나 구문, list() 함수를 사용한다.
print(range(10))
print(list(range(10)))
print(list(range(1, 10, 2)))>>>range(0, 10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 3, 5, 7, 9]
**Exercise : 문장 속에 나타나는 문자 갯수를 카운팅하여 딕셔너리 형태로 표현
message = 'It was a bright cold day in April, and the clocks were striking thirteen.'
msg_dict = dict() # {}
for msg in message:
print(msg, message.count(msg))
msg_dict[msg] = message.count(msg) # key = value
print(msg_dict)>>>I 1
t 6
13
w 2
a 4
s 3
13
a 4
13
b 1
r 5
i 6
g 2
h 3
t 6
13
c 3
o 2
l 3
d 3
13
d 3
a 4
y 1
13
i 6
n 4
13
A 1
p 1
r 5
i 6
l 3
, 1
13
a 4
n 4
d 3
13
t 6
h 3
e 5
13
c 3
l 3
o 2
c 3
k 2
s 3
13
w 2
e 5
r 5
e 5
13
s 3
t 6
r 5
i 6
k 2
i 6
n 4
g 2
13
t 6
h 3
i 6
r 5
t 6
e 5
e 5
n 4
. 1
{'I': 1, 't': 6, ' ': 13, 'w': 2, 'a': 4, 's': 3, 'b': 1, 'r': 5, 'i': 6, 'g': 2, 'h': 3, 'c': 3, 'o': 2, 'l': 3, 'd': 3, 'y': 1, 'n': 4, 'A': 1, 'p': 1, ',': 1, 'e': 5, 'k': 2, '.': 1}
**파이썬 Coding Convention
-PEP8
https://www.python.org/dev/peps/pep-0008/
-
파이썬 코드 개선을 위한 제안서이며 코딩 기준을 제시함
-
PEP8 파이썬 코딩 컨벤션에서 제시하는 기준들
-flake8 모듈로 체크
pip install flake8
flake8 5_charCountDict.py
5_charCountDict.py:1:80: E501 line too long (85 > 79 characters)
5_charCountDict.py:3:18: E261 at least two spaces before inline comment
5_charCountDict.py:6:39: E261 at least two spaces before inline comment
5_charCountDict.py:9:1: W391 blank line at end of file
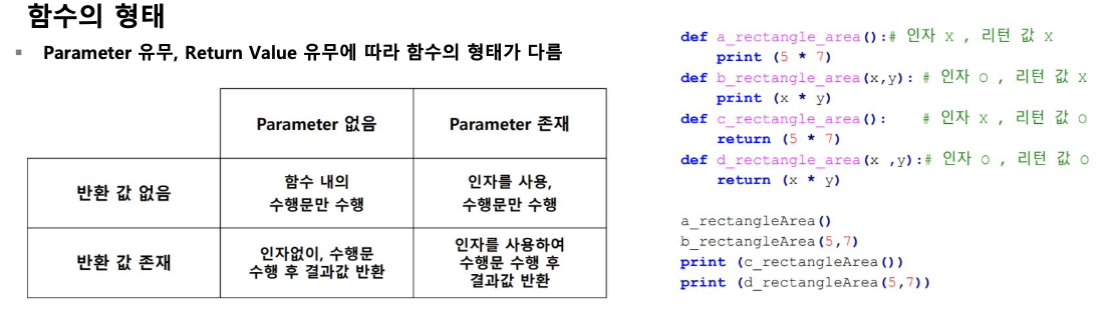
**함수
-
어떤 일을 수행하는 코드의 덩어리
-
코드를 논리적인 단위로 분리
-
캡슐화 : 인터페이스만 알면 타인의 코드를 사용할 수 있다.
-
코드 재사용을 위함
**parameter vs argument
-
Parameter : 함수의 입력 값 인터페이스
-
Argument : 실제 Parameter에 대입된 값
**local variable(지역변수) vs global variable(전역변수)
-
지역변수는 함수 내부에서만 사용
-
전역변수는 프로그램 전체에서 사용, 함수 내부에서도 사용 가능, 하지만 함수 내에 전역변수와 같은 이름의 변수를 선언하면 새로운 지역변수가 생긴다.
-
함수 내에서 전역변수 사용 시 global 키워드 사용

# list에 저장된 값의 평균을 계산하는 함수 정의
def my_average(numbers):
print(numbers)
total = 0
for num in numbers:
total += num
avg = total / len(numbers)
return int(avg)
my_list = [20, 50, 60, 100, 30]
result = my_average(my_list)
print('평균값은 {}'.format(result))>>>[20, 50, 60, 100, 30]
평균값은 52
->main함수를 만드는 것을 더 권장한다.
# list에 저장된 값의 평균을 계산하는 함수 정의
def my_average(numbers):
print(numbers)
total = 0
for num in numbers:
total += num
avg = total / len(numbers)
return int(avg)
def main():
my_list = [20, 50, 60, 100, 30]
result = my_average(my_list)
print('평균값은 {}'.format(result))
main()>>>[20, 50, 60, 100, 30]
평균값은 52
**함수 파라미터
-
위치 파라미터
-
키워드 파라미터
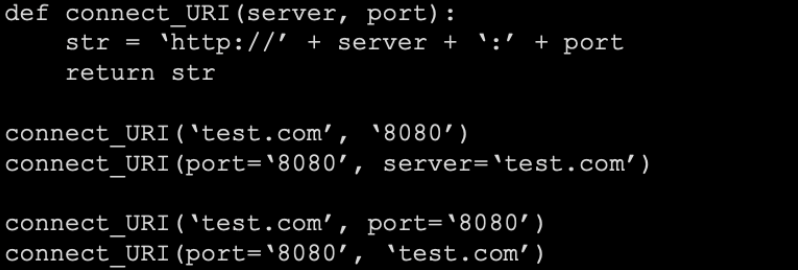
# 위치 파라미터
def connect(server, port):
url = f'http://{server}:{port}'
return url
print(connect('localhost','8080'))
print(connect(port='80', server='aa.com'))
print(connect('naver.com',port='8090'))>>>http://localhost:8080
# Argument Default Value
def add(a=10, b=20):
return a + b
def minus(a=10, b=30):
return b - a
print(add(40, 50))
print(add())
print(minus(100))
print(minus(b=100))>>>90
30
-70
90
--함수 파라미터 : 가변 파라미터
*p : typle type parameter
**p : dict type parameter

# 가변(파라미터의 갯수가 정해지지 않음) 파라미터 - tuple 타입
def kwargs_test(a, b, *p):
print(type(p))
print(a, b, p)
return a + b + sum(p)
print(kwargs_test(10, 20))
print(kwargs_test(10, 20, 30, 40))>>><class 'tuple'>
10 20 ()
30
<class 'tuple'>
10 20 (30, 40)
100
# 가변 파라미터 - dict 타입
def kwargs_dict(**p):
print(p, type(p))
for k, v in p.items():
print(k, v)
kwargs_dict(a=100, b=300, c=400)>>>{'a': 100, 'b': 300, 'c': 400} <class 'dict'>
a 100
b 300
c 400
**코랩(GPU대신 구글자원을 이용해서 사용) Colab - 구글 드라이브에 저장
command + enter = 그 선택된 셀만 실행
shift + enter = 선택된 셀 실행 + 아래에 커서 이동
alt + enter : 해당 셀을 실행하고 새로운 셀을 추가

인공지능, 딥러닝으로 대용량의 데이터를 처리해야 할때
runtime -> change runtime type -> GPU로 변경해서 사용( 장시간 미사용시 세션이 만료되는 단점이 있음)
**return값을 튜플로 여러 인자로 할수있다.

# 값을 여러개 return - tuple type
def swap(a, b):
return b, a
result = swap(10, 20)
print(result, type(result))
x, y = swap(10, 20)
print(f'X = {x} Y = {y}')>>>(20, 10) <class 'tuple'>
X = 20 Y = 10
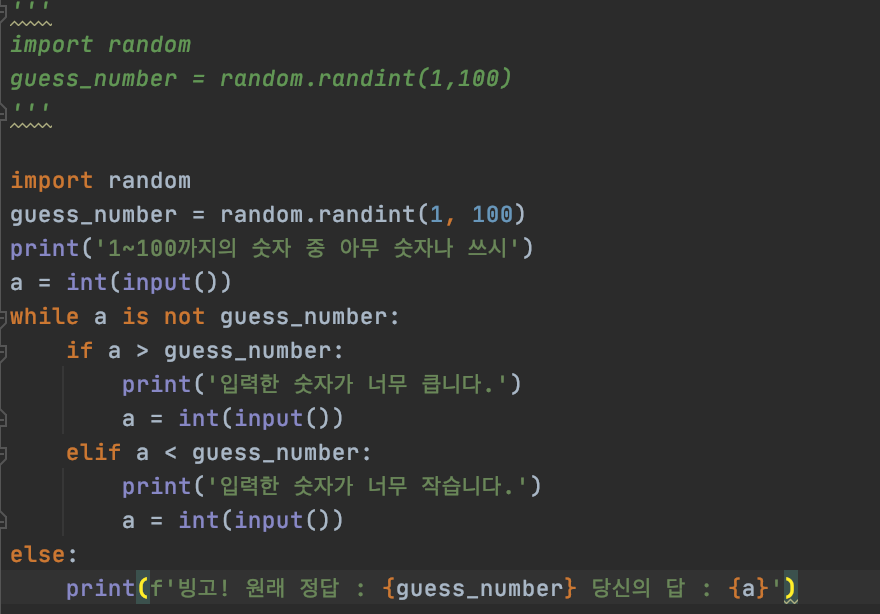
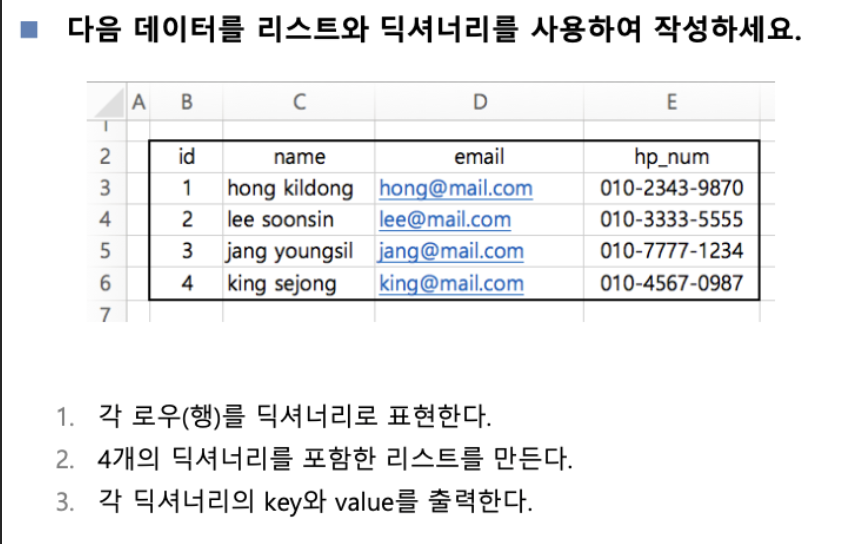
**오늘의 과제
1/1까지 63p guess게임과 , 64p 구구단 입력 과제, 86p 페이지 리스트와 딕셔너리 사용



12/31~1/3 휴강기간동안 html, css, javascript, bootstrap(css library) 각각의 역할은 무엇인지? 간단하게 코드 작성
css 선택자(selector)
http에서 GET방식과 POST방식의 차이점은 무엇인지?
1월 11일 : django 시작
'CLOUD > Python' 카테고리의 다른 글
| 1/11 파이썬 6차시 - 웹스크래핑(MariaDB연동), 시각화 (0) | 2021.01.11 |
|---|---|
| 1/6 파이썬 5차시 - 웹스크래핑(csv, xml, json타입 처리), 데이터 분석 (0) | 2021.01.06 |
| 1/5 파이썬 4차시 - 깃파이참연동, 모듈과 패키지, 예외처리, 파일다루기, 웹스크래핑 (0) | 2021.01.05 |
| 1/4 파이썬 3차시 - 함수가이드라인, pythonic code, 람다, 객체와클래스, 모듈과 패키지 (0) | 2021.01.04 |
| 12/29 파이썬 1차시 - 개요, 숫자, 문자, 리스트 (0) | 2020.12.29 |