파이썬 - 아나콘다(16GB)
아나콘다가 용량이 너무커서 노트북이 버거워한다면 colab사용
Google Colab -> 대신 디버깅이 불편함
jupyter
1주차 - 12월 29, 30 1월 4, 5, 6 -> 파이썬 프로그래밍
2주차 - 1/11~1/15 : Django(웹 프로그래밍), html, css, javascript는 자세하게 x
=> 쉬는 연휴동안 생활코딩에서 html, css, js공부해보기
개발환경 설정
파이썬 SDK 개발 kit
python.org에서 다운로드 받는 개발 kit : 파이썬에서 기본적으로 제공하는 내부모듈만 포함하고 있음
데이터분석(판다스), 시각화(시본,보케), 인공지능(텐서플로우), 웹스크래핑 : 외부 모듈을 사용해야 함(third party)
Anaconda : 기본모듈 + 외부모듈이 포함된 개발 kit -> 위의 라이브러리가 다 포함되어 있음
blog.naver.com/vega2k
c:\mypython 폴더를 생성하고 pdf와 zip은 mypython폴더에 다운로드 받아주세요
Editor (IDE - integrated development environment) : 통합개발환경 -> pycharm
PyPI(python package index) : python기반 open source repository(저장소)
python : pip install tensorflow
javascript : npmjs (node package manager) -> npm i jquery
java : maven repository -> pom.xml에 포함
**버전확인(아나콘다 인스톨 완료)
python --version -> Python 3.8.5
pip --version -> pip 20.2.4 from /Users/mhee4/opt/anaconda3/lib/python3.8/site-packages/pip (python 3.8)
pycharm에 anaconda의 python을 연결
file -> settings -> project -> project interpreter
-> 설정아이콘 -> Add -> 왼쪽메뉴의 System interpreter
-> c:\ProgramData\Anaconda3\python.exe -> ok
맥북 참고
python console창에서 ipython으로 코드작성가능
terminal창에서 pip --version 실행
**google colab 설치
**jupyter설치
cd mypython
jupyter notebook
run 단축키 = command + enter : 해당 셀만 실행
shift + enter : 해당 셀을 실행하고, 커서를 아래로 이동
alt + enter : 해당 셀을 실행하고 새로운 셀을 추가

=>데이터 사이언스, 웹 스크래핑할 때 주로 사용
**python 프로그래밍 진도
자료구조와 함수, pythonic code 작성하기, 객체와 클래스, 모듈과 패키지 pip, 예외처리와 로깅, 파일 다루기, web scraping(csv파일 다루기, xml과 json)
1일차 : 개요, 숫자, 문자, 리스트
2일차 : 제어문, 자료구조, 코딩컨벤션, 함수, 함수가이드라인
3일차 : pythonic code, 람다, 객체와클래스, 모듈과 패키지
4일차 : 예외처리, 파일다루기, 웹스크래핑
5일차 : 웹스크래핑(csv, xml, json 타입 처리)
String s1 = new String("hello");
String s2 = new String("hello");
s1 == s2 false
String s1="hello";
String s2="hello";
s1 == s2 true
파이썬 tab키 -> 자동완성
주석 -> # line, '''block
a = '76.1'
b = 76.1
print(a + b) -> 에러뜸(자바는 가능)
print(a, b) -> 76.1 76.1
**CLI(Command Line Interface)
print('더하고 싶은 숫자를 입력하세요')
value1 = int(input())
print(type(value1))
.py실행 단축키 : ctrl+shift +f10
**연습문제
def transfer(n1):
return ((9/5)*n1)+32
print('변환하고 싶은 섭씨 온도를 입력해 주세요:')
n = float(input())
answer = transfer(n)
print('화씨 온도는', '%0.2f' % answer , '입니다.')
=> '화씨온도 ', round(answer, 2) && '화씨온도 {:.2f}'.format(answer)도 가능>>>변환하고 싶은 섭씨 온도를 입력해 주세요:
32.2
화씨 온도는 89.96 입니다

# escape 문자
greet = 'Hello' *4+ '\n'
end = '\tGood \'Bye\' !!'
end2 = "\t Good 'Morning' !!"
print(greet + end + end2)>>>HelloHelloHelloHello
Good 'Bye' !! Good 'Morning' !!
# bool 타입과 str 타입
is_flag = False
my_str = 'True'
print(type(is_flag), type(my_str))
if not is_flag:
print(my_str)>>><class 'bool'> <class 'str'>
True
# 문자열 인덱스(오프셋)
greeting = 'hello world'
print('문자열 길이 {} 0번째 인덱스 값은 {}'.format(len(greeting), greeting[0]))
# c언어 스타일
print('파이썬 %s' % greeting)
print('문자열 길이 %i' % len(greeting))
# 3.6 버전이후
print(f'문자열 길이 {len(greeting)}, 1번째 인덱스 값은 {greeting[1]}')>>>문자열 길이 11, 0번째 인덱스 값은 h
파이썬 hello world
문자열 길이 11
문자열 길이 11, 1번째 인덱스 값은 e
# 문자열 인덱스 슬라이싱 [start:end:step]
print(f'greeting[0:5] = {greeting[0:5]}')
print(f'greeting[6:11] = {greeting[6:11]}')
print(f'greeting[6:] = {greeting[6:]}')
print(f'greeting[:5] = {greeting[:5]}')
print(greeting[::2])>>>greeting[0:5] = hello
greeting[6:11] = world
greeting[6:] = world
greeting[:5] = hello
hlowrd(한칸씩 뛰어넘기) -> 기본 디폴드값 [::1]
->파이썬 기본 단축키

# 음수값의 인덱스
print(f'greeting[-1:] = {greeting[-1:]}')
print(f'greeting[-2:] = {greeting[-2:]}')
# 문자열이 역순으로 바뀐
print(f'greeting[::-1] = {greeting[::-1]}')>>>greeting[-1:] = d
greeting[-2:] = ld
greeting[::-1] = dlrow olleh
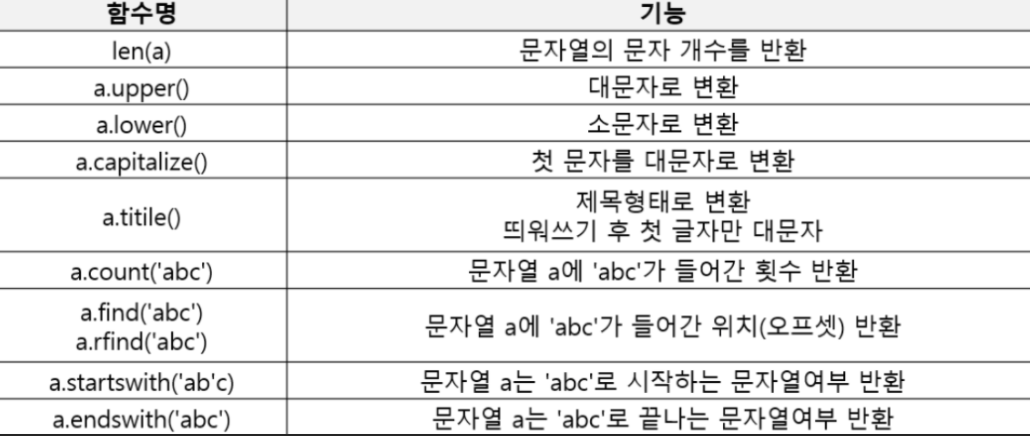
# 문자열 여러가지 함수들
word = 'Good manufacturing Practice Good'
print(f'대문자로 변환 = {word.upper()}')
result = word.upper()
print(word, ' ', result)
print(f'소문자로 변환 = {word.lower()}')
print(word.title())
print(word.find('G'))
print(word.rfind('G'))
print(word.count('G'))
# 공백을 기준으로 배열로 나눠줌
word_list = word.split()
print(word_list, type(word_list))
word2 = 'Good/manufacturing/Practice/Good'
print(word2.split('/'))
# strip => 공백제거
word3 = ' hello python '
print(len(word3), len(word3.strip()), word3.strip())
print(len(word3.rstrip()), word3.rstrip())
#시작, 끝문자
print(word.startswith('G'))
print(word.endswith('G'))
for val in word:
print(val, word.count(val))
print(word_list)
for w in word_list:
print(w)>>>대문자로 변환 = GOOD MANUFACTURING PRACTICE GOOD
Good manufacturing Practice Good GOOD MANUFACTURING PRACTICE GOOD
소문자로 변환 = good manufacturing practice good
Good Manufacturing Practice Good
0
28
2
['Good', 'manufacturing', 'Practice', 'Good'] <class 'list'>
['Good', 'manufacturing', 'Practice', 'Good']
14 12 hello python
13 hello python
True
False
G 2
o 4
o 4
d 2
3
m 1
a 3
n 2
u 2
f 1
a 3
c 3
t 2
u 2
r 2
i 2
n 2
g 1
3
P 1
r 2
a 3
c 3
t 2
i 2
c 3
e 1
3
G 2
o 4
o 4
d 2
['Good', 'manufacturing', 'Practice', 'Good']
Good
manufacturing
Practice
Good
-**포맷팅


print('0번째 인덱스 값은 {1}, 문자열 길이 {0}'.format(len(greeting), greeting[0]))>>0번째 인덱스 값은 h, 문자열 길이 11
**리스트
# list of mixed items
anything = [10, 'hello', 'ahoy', 123.45] (가능은 한데 잘 안씀)
num_list = [10, 20, 40, 50, 60]
print(type(num_list), num_list)
print(num_list[0], num_list[0:3], num_list[3:])
for num in num_list:
print(num)>>><class 'list'> [10, 20, 40, 50, 60]
10 [10, 20, 40] [50, 60]
10
20
40
50
60
# enumerate -> index값 구할 때
for idx, num in enumerate(num_list):
print(idx, num)>>>0 10
1 20
2 40
3 50
4 60
str_list = ['python', 'java', 'kotlin', 'c++', 'scalar']
print(type(str_list), str_list)
# index로 list의 엘리먼트 값을 변경
str_list[1] = 'javascript'
print(str_list[1], str_list[2:4])
for idx, val in enumerate(str_list):
print(idx, val)
# 엘리먼트 추가
str_list.append('Cobol') -> 끝에다 붙이기
str_list.insert(1, 'Typescript') -> 원하는 index에 삽입
print(str_list)>>><class 'list'> ['python', 'java', 'kotlin', 'c++', 'scalar']
javascript ['kotlin', 'c++']
0 python
1 javascript
2 kotlin
3 c++
4 scalar
0 python
1 Typescript
2 javascript
3 kotlin
4 c++
5 scalar
6 Cobol
mix_list = [100, 3.14, True, '파이썬']
for mix in mix_list:
print(type(mix), mix)>>><class 'int'> 100
<class 'float'> 3.14
<class 'bool'> True
<class 'str'> 파이썬
**연습문제(yesterday) -> 숙제검사....
이름_yesterdaycount 숙제
'''
yesterday.txt 파일을 읽어서
YESTERDAY 라는 단어가 몇번 나왔는지 yesterday_lyric.upper().count('YESTERDAY')
Yesterday 라는 단어가 몇번 나왔는지 yesterday_lyric.count('Yesterday')
yesterday 라는 단어가 몇번 나왔는지 yesterday_lyric.lower().count('yesterday')
'''
myFile = open('yesterday.txt','r')
yesterday_lyric = myFile.read()
a = yesterday_lyric.upper().count('YESTERDAY')
b = yesterday_lyric.count('Yesterday')
c = yesterday_lyric.lower().count('yesterday')
print(a,b,c)
myFile.close()
**유튜브 추천 -> 나도코딩 파이썬, 테크보이 워니, 조코딩, 노마드 코더(프론트엔드), 생활코딩 머신러닝 야학
'CLOUD > Python' 카테고리의 다른 글
| 1/11 파이썬 6차시 - 웹스크래핑(MariaDB연동), 시각화 (0) | 2021.01.11 |
|---|---|
| 1/6 파이썬 5차시 - 웹스크래핑(csv, xml, json타입 처리), 데이터 분석 (0) | 2021.01.06 |
| 1/5 파이썬 4차시 - 깃파이참연동, 모듈과 패키지, 예외처리, 파일다루기, 웹스크래핑 (0) | 2021.01.05 |
| 1/4 파이썬 3차시 - 함수가이드라인, pythonic code, 람다, 객체와클래스, 모듈과 패키지 (0) | 2021.01.04 |
| 12/30 파이썬 2차시 - 제어문, 자료구조, 코딩컨벤션, 함수, colab (0) | 2020.12.30 |