12/7 Spring Boot 1차시 + 12/8 Spring Boot 2차시
** 앞으로 10일동안
-
Spring Boot - 게시판 예제
-
MSA
-
Node.js
-
포트폴리오 만들기
이클립스 기반 Spring 1 (기존 설정을 내가 직접 다 해줌)
- > Spring2(Spring STS3.xx) - Spring MVC만 설정해도 라이브러리 설정파일이 알아서 설정됨
- > Spring Boot(STS 4.xx)하나만으로 실행이 가능하게 만들자
maven -> gradle
mybatis -> JPA
tiles -> Thymeleaf
**power shell창 띄우기
java -jar +sapce바 +tab키로 저장된 주소 불러오기(extracting.jar압축파일 풀기) -> 다운
new -> Spring Starter Project

-
java dev tools library만 일단 설정하기
**board만들기

C:\Users\kosta\.gradle\caches\modules-2\files-2.1\org.projectlombok
--lombok.jar가 있는 곳에서 java -jar lombok 설치
**타임리프(Thymeleaf)
-
Thymeleaf는 스프링부트가 자동 설정을 지원하는 웹 템플릿 엔진입니다. HTML문서에 HTML5 문법으로 서버쪽 로직을 수행하고 적용시킬 수 있습니다.
-
HTML 디자인에 전혀 영향을 미치지 않고 웹 템플릿 엔진을 통해 HTML을 생성할 수 있습니다.
-
템플릿 엔진, th:xx 형식으로 속성을 html태그에 추가하여 값을 처리할 수 있습니다.
-
JSP, Groovy 등 다른 템플릿도 스프링 부트에서 사용 가능하지만 thymeleaf가 가장 많이 사용된다.
**JSP를 권장하지 않는 이유
-
JAR 패키징 할 때는 동작하지 않고, WAR 패키징 해야 함.
-
Undertow(Servlet Engine)는 JSP를 지원하지 않음
--2차시(+fileUpDownload)
log4j 추가 implementation group : org.bgee.log4jdbc-log4j2 4.1 1.16
// https://mvnrepository.com/artifact/org.bgee.log4jdbc-log4j2/log4jdbc-log4j2-jdbc4.1
implementation group: 'org.bgee.log4jdbc-log4j2', name: 'log4jdbc-log4j2-jdbc4.1', version: '1.16'
resources 안에 3개 문서 넣어주기
--JPA
mybatis : SQL실행결과를 자바객체에 매핑시켜주는 것
JPA(Java Persistence API) : ORM(Object Relation Mapping)은 애플리케이션의 클래스와 데이터베이스의 테이블 사이의 매핑 정보를 기술한 메타데이터를 사용하여 자바 객체를 SQL 데이터베이스의 테이블에 자동으로 영속화 해주는 기술(매핑시켜주는 기술)

-
JDBC를 직접 사용하는 방식
-
JPA로 도메인 모델을 사용하는 방식
*ORM의 장점
-
생산성 : 매핑을 하면 데이터 입출력이 정말 쉬워진다.
-
유지보수성 : 코드가 굉장히 간결해지고, 코드량이 줄어 유지보수성이 높아진다.
-
성능 : 객체와 테이블 사이에 캐시가 존재하여 중복 혹은 필요없는 데이터 변경 요청이 들어오면 반영하지 않고, 데이터가 변경될 여지가 있을 때만 변경 함으로 효율적이다.
-
벤더 독립성 : Hibernate가 어떠한 데이터베이스에 맞게 SQL을 자동으로 생성함으로 DBMS에 독립적이다.
*ORM의 단점(중급개발자 이상만 주로 사용함)
-
높은 학습비용 : SQL, Hibernate, JPA 전부 잘 알고 있어야 제대로 활용할 수 있기에 학습하는데 높은 난이도와 많은 시간이 소요된다.
-
특정 데이터베이스 기능을 사용할 수 없다.(오라클 함수, 튜닝기능)
-
객체지향 설계가 필요하다.
-
스프링 데이터 JPA
💨스프링 데이터 JPA란 JPA를 스프링에서 쉽게 사용할 수 있도록 해주는 라이브러리이다.
💨Hibernate와 같은 JPA 프로바이더를 직접 사용할 경우 엔티티 매니저를 설정하고 이용하는 등 여러가지 진입장벽이 있다.
💨스프링 데이터 JPA는 리포지터리(Repository)라는 인터페이스를 제공한다.
💨리포지터리(Repository)만 상속받아 정해진 규칙에 맞게 메서드 작성하면 개발자가 작성해야 할 코드가 완성된다.
-
application.properties 설정 추가하기

-
DatabaseConfiguration 클래스에 JPA 설정 빈 등록하기

-
엔티티 생성하기, board.entity 패키지 생성 후 BoardEntity, BoardFileEntity 클래스 생성


-
@Entity 어노테이션은 해당 클래스가 JPA의 엔티티임을 나타낸다.
-
@Table 어노테이션은 테이블과 매핑되도록 나타낸다.
-
@ID 어노테이션은 기본키임을 나타낸다.
-
@GenerateValue, @SequenceGenerator 시퀀스 생성 및 기본키 생성 전략을 나타낸다.
-
@OneToMany는 1:N의 관계를 표현하는 JPA 어노테이션이다.
-
@JoinColumn 어노테이션은 릴레이션 관계가 있는 테이블의 컬럼을 지정한다.
컨트롤러 작성 -> 서비스 작성 -> 리포지터리 작성
-
CurdRepository
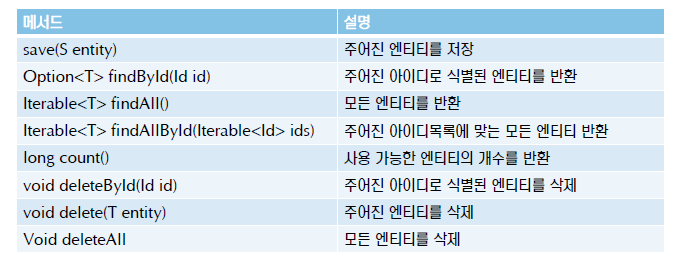
**쿼리 메서드 작성
-
스프링 데이터 JPA는 규칙에 맞게 메서드를 추가하면 그 메서드의 이름으로 쿼리를 생성하는 기능을 제공한다.
-
쿼리 메서드는 find..By, read..By, query..By, count..By, get..By로 시작해야 한다.
-
첫번째 By 뒤쪽은 컬럼 이름으로 구성된다.
-
BoardEntity의 제목으로 검색하려면 And 키워드를 사용한다.
-
=>findByTitleAndContents(String title, String contents);
**@Query사용
-
메서드 이름이 복잡하거나 쿼리 메서드로 표현하기 힘들다면 @Query어노테이션으로 쿼리를 직접 작성할 수 있다.
-
이때 쿼리는 데이터베이스에 맞는 SQL을 이용할 수 있다.



'FULLSTACK > SPRING' 카테고리의 다른 글
| Spring Boot - AJAX 통신 (0) | 2021.06.20 |
|---|---|
| Spring Boot - Spring Security 설정 (0) | 2021.06.20 |
| STS기반 SPRING - 구멍가게코딩단 책과 함께합니다 (0) | 2020.11.13 |
| SPRING 4차시 - AOP, TRANSACTION, FILE UP/DOWN (0) | 2020.11.13 |
| SPRING 3차시 - DB연결, RESTful방식 (0) | 2020.11.13 |