**그룹함수
-sum(), avg(), max(), count()
-SELECT sum(salary), FROM employees;
**GROUP BY절
부서별로(where : 개인별로)
~주의사항 : 컬럼내역은 그룹함수 또는 GROUP BY 사용한 칼럼
-부서별 평균급여를 검색하라.
->SELECT department_id, avg(salary), last_name(x, 개인단위는 출력불가) // 그룹에서 사용한 칼럼이나 그룹함수만 사용가능하다.
FROM employees
GROUP BY department_id;
퀴즈 hr> 부서별로 사원의 수와 커미션을 받는 사원의 수를 검색하라.
SELECT department_id, count(*), count(commission_pct) //count(salary)라 해도 됨.
FROM employees
GROUP BY department_id
ORDER BY department_id;
<mission kosta202>
-
화학과 학년별 평균 학점을 검색하라.
-
각 학과별 학생수를 검색하라.
-
화학과 생물학과 학생을 4.5환산 학점의 평균을 각각 검색하라.
SELECT syear, avg(avr) FROM student
WHERE major = '화학'
GROUP BY syear
ORDER BY major, syear;
SELECT major, count(*) FROM student
GROUP BY major
ORDER BY major;
SELECT major, avg((avr/4.0)*4.5) FROM student
WHERE major IN ('화학', '생물')
GROUP BY major;
**having절
-전체 그룹에서 일부 그룹만 추출하기 위해서
-부서별 급여 평균이 5000 미만인 부서의 부서번호와 평균급여를 검색하라.
-> SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id
HAVING AVG(salary) < 5000;
<mission kosta202>
-
화학과를 제외한 학생들의 과별 평점평균을 검색하라.
-
화학과를 제외한 각 학과별 평점 중에 평점이 2.0 이상 학과정보를 검색하라.
-
근무중인 직원 3명 이상인 부서를 검색하라.(emp)
SELECT major, ROUND(avg(avr),2) FROM student
HAVING major != '화학'
GROUP BY major;
SELECT major, avg(avr) FROM student
GROUP BY major
HAVING major != '화학'
AND AVG(avr) >=2.0;
SELECT dno, count(*) FROM emp
GROUP BY dno
HAVING count(*) >=3; //where절 쓸 수 없음.
**문자 함수
-LOWER() -> 소문자로 변환
-> SELECT 'DataBase', LOWER('DataBase') FROM dual;
-UPPER() -> 대문자로 변환
-> SELECT 'DataBase', UPPER('DataBase') FROM dual;
-SUBSTR() -> 부분문자열 추출
-> SELECT SUBSTR('abcdef',2, 4) FROM dual; => 인덱스 1부터, 인덱스 갯수
-LENGTH() -> 문자열 길이
-LPAD(), RPAD() -> 데이터 빈 공간을 특정 문자로 채우는 것
-> SELECT 'Oracle',
LPAD('Oracle', 10, '#') AS LPAD_1,
RPAD('Oracle', 10, '#') AS RPAD_1
FROM dual;
퀴즈 kosta202 > 과목명 마지막 글자를 제외하고 출력하라.(course)
-> SELECT cname, SUBSTR(cname,1,LENGTH(cname)-1) FROM course;
**숫자 함수
-MOD -> 나머지값 리턴
->SELECT MOD(10,3) FROM dual;
-ROUND -> 반올림값 리턴
->SELECT ROUND(5443.325543, 2) FROM dual; //5443.33
->SELECT ROUND(5443.325543, -2) FROM dual; //5400
-TRUNC -> 특정위치 버리는것
->SELECT TRUNC(1234.5678) FROM dual; //소숫점 없어짐
-> SELECT TRUNC(1234.5678, 1) FROM dual; //1234.5
**날짜 함수
-SYSDATE => 현재시간을 출력하는 함수
-> SELECT SYSDATE -1 "어제", SYSDATE "오늘", SYSDATE+1"내일"
FROM dual;
퀴즈 hr> 사원의 근속년을 출력하라.
->SELECT LAST_NAME, hire_date,ROUND((SYSDATE-hire_date)/365,0) FROM EMPLOYEES;
**변환 함수
-TO_CHAR() : 숫자, 날짜 => 문자열 반환
-> SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD') FROM dual;
-> SELECT TO_CHAR(5000000000000, '$999,999,999') FROM dual;
퀴즈 hr> 07년에 입사한 사원의 목록을 출력하라.
SELECT TO_CHAR(hire_date, 'YY-MM-DD') FROM employees
WHERE '07-01-01'<=hire_date AND '07-12-31'>=hire_date;
->SELECT * FROM employees
WHERE TO CHAR(hire_date, 'YYYY') = '2007';
**NVL() : NULL을 0 또는 디폴트값으로 변환 //null값이 있으면 연산이 안되기때문
-> SELECT employee_id, salary, NVL(commission_pct,0)
FROM employees;
퀴즈> 사원의 연봉을 출력하라. ((월급여)*12) + (월급여*commission))
SELECT last_name, JOB_ID, salary*12 + salary*NVL(COMMISSION_PCT,0)
FROM employees;
**DECODE 함수
->SELECT job_id, DECODE(job_id, 'SA_MAN', 'Sales Dept',
'SH_CLERK', 'Sales Dept', 'Another')
FROM employees;
-CASE WHEN
-> SELECT job_id,
CASE job_id
WHEN 'SA_MAN' THEN 'Sales Dept'
WHEN 'SH_CLERK' THEN 'Sales Dept'
ELSE 'Another2'
END "CASE"
FROM employees;
퀴즈 hr> department 부서 (department_id)
10 -> Accounting
20 -> Sales
30 -> Innovation
Another
SELECT last_name, department_id, DECODE(department_id, 10, 'Accounting',20,'Sales',30,'Innovation','Another')
FROM employees;
-- 잊기 전에 한 번 더 정답
SQL_2
-- 6-1
SELECT EMPNO,
RPAD(SUBSTR(EMPNO, 1, 2), 4, '*') AS MASKING_EMPNO,
ENAME,
RPAD(SUBSTR(ENAME, 1, 1), LENGTH(ENAME), '*') AS MASKING_ENAME
FROM EMP
WHERE LENGTH(ENAME) >= 5
AND LENGTH(ENAME) < 6;
-- 6-2
SELECT EMPNO, ENAME, SAL,
TRUNC(SAL / 21.5, 2) AS DAY_PAY,
ROUND(SAL / 21.5 / 8, 1) AS TIME_PAY
FROM EMP;
-- 6-3
SELECT EMPNO, ENAME, HIREDATE,
TO_CHAR(NEXT_DAY(ADD_MONTHS(HIREDATE, 3), '월요일'), 'YYYY-MM-DD') AS R_JOB,
NVL(TO_CHAR(COMM), 'N/A') AS COMM
FROM EMP;
**NEXT_DAY(찾을 날짜의 month, 요일)
-- 6-4
SELECT EMPNO, ENAME, MGR,
CASE
WHEN MGR IS NULL THEN '0000'
WHEN SUBSTR(MGR, 1, 2) = '78' THEN '8888' ->많이씀
WHEN SUBSTR(MGR, 1, 2) = '77' THEN '7777'
WHEN SUBSTR(MGR, 1, 2) = '76' THEN '6666'
WHEN SUBSTR(MGR, 1, 2) = '75' THEN '5555'
ELSE TO_CHAR(MGR)
END AS CHG_MGR
FROM EMP;
DDL vs DML : 트랜잭션 가능 여부
**DDL(data definition language) - 자료 정의 언어 (테이블 생성 삭제) : 트랜잭션 적용이 불가 -> 롤백불가(복귀불가) 한번 생성하면 되돌릴 수 없음.
-테이블 생성
CREATE/ DROP
CREATE TABLE 테이블 이름(
컬럼명1 데이터형,
컬럼명2 데이터형,
컬럼명3 데이터형
)
*데이터형(자료형)
-문자형 : CHAR(size)-데이터 크기가 명확히 있을때(남/여), VARCHAR2(size) -그 외 가변형
-숫자형 : NUMBER, NUMBER(w), NUMBER(w,d)
-날짜형 : DATE, TIMESTAMP
-대용량 : (이미지, 파일) : LOB, BLOB
*테이블 복사
CREATE TABLE emp01
AS SELECT * FROM employees; (기존 데이터 내용 포함 복사)
*테이블 구조 복사
CREATE TABLE emp02
AS SELECT * FROM employees Where 1=0;
*테이블 구조 수정
-칼럼 추가
->ALTER TABLE emp02
ADD(job VARCHAR2(50));
-컬럼 수정
->ALTER TABLE emp02
MODIFY(job VARCHAR2(100));
-컬럼삭제
->ALTER TABLE emp02
DROP COLUMN job;
-테이블 삭제
-> DROP TABLE emp02 PURGE; //삭제하고 남은 찌꺼기까지 삭제하고싶을때
-테이블 데이터 삭제
-> TRUNCATE TABLE emp01; //DDL(트랜잭션 적용 불가능) - 한번 삭제되면 인생도 같이 삭제됨
-> DELETE FROM emp01; //DML(트랜잭션 적용 가능) -> 롤백하면 다시 돌아옴(물론 commit하기 이전의 이야기)
-테이블 이름 변경
->RENAME emp01 TO emp00;
**DML (테이블 안에 있는 데이터를 수정) - INSERT, UPDATE, DELETE(수정 삭제는 where써야함)
--CRUD작업을 위해 이런 간단한 로직 외우기
-CREATE TABLE dept01
AS SELECT * FROM departments;
INSERT
-> INSERT INTO dept01 VALUES(300, 'Developer', 100, 10);
-> INSERT INTO dept01(department_id, department_name)
VALUES(600, 'Developer2'); //두개의 열에만 데이터를 넣고 싶을때
-UPDATE
->UPDATE 테이블명 SET 컬럼명=수정값, 컬럼명=수정값
WHERE 수정대상
->UPDATE dept01 SET department_name = 'IT Service'
WHERE department_id = 300;
퀴즈 hr>emp00 테이블에서 salary 3000이상 대상자에게 salary에 10%인상 해줍시다~
-
24000 -> 26400
UPDATE emp00 SET salary = salary*1.1
WHERE salary>= 3000;
-DELETE문
-> DELETE FROM 테이블명 WHERE 삭제대상
퀴즈 hr> dept01 테이블에서 부서이름 'IT Service'값을 가진 로우 삭제
->DELETE FROM dept01 WHERE department_name='IT Service';
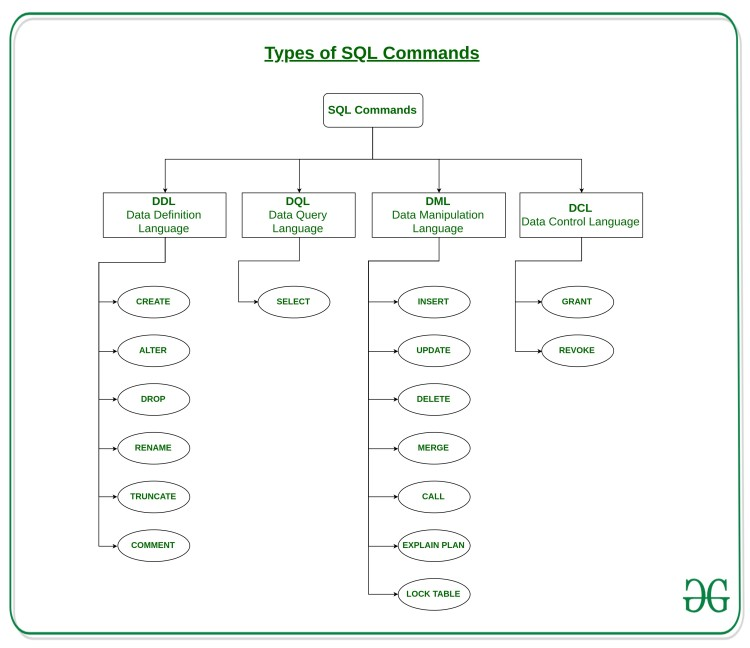
CREATE, READ, UPDATE, DELETE(CRUD)
★★오늘의 하이라이트 제약조건
데이터의 무결성을 위해
-데이터를 추가, 삭제, 수정하는 가운데 DB의 무결성을 유지
CREATE TABLE emp01(
empno NUMBER,
ename VARCHAR2(20),
job VARCHAR2(20),
deptno NUMBER
)
INSERT INTO emp01 VALUES(NULL, NULL, 'IT', 30); //이런 의미없는 데이터를 거부할수없음
CREATE TABLE emp02(
empno NUMBER NOT NULL, //공백이 들어오지 못하도록
ename VARCHAR2(20) NOT NULL,
job VARCHAR2(20),
deptno NUMBER
)
INSERT INTO emp02 VALUES(NULL, NULL, 'IT', 30); //데이터 들어갈 수 없음
INSERT INTO emp02 VALUES(100, 'kim', 'IT', 30);
INSERT INTO emp02 VALUES(100, 'park', 'IT', 30); //이미 데이터 값이 들어가면 회복불가-사원번호가 동일한 실수발생 : 데이터가 들어오기 전에 막았어야 했음.
CREATE TABLE emp03(
empno NUMBER UNIQUE, // 중복된 값이 들어오지 못하도록
ename VARCHAR2(20) NOT NULL,
job VARCHAR2(20),
deptno NUMBER
)
INSERT INTO emp03 VALUES(100, 'kim', 'IT', 30);
INSERT INTO emp03 VALUES(100, 'park', 'IT', 30);
-
PRIMARY KEY 제약조건 //주키
-
-> UNIQUE + NOT NULL (중복되지 않고 입력되어야 한다.)
CREATE TABLE emp04(
empno NUMBER PRIMARY KEY,
ename VARCHAR2(20) NOT NULL,
job VARCHAR2(20),
deptno NUMBER
)
INSERT INTO emp04 VALUES(100, 'park', 'IT', 30000); //30000이라는 부서번호는 없음!!
-
FOREIGN KEY 제약조건 ( 부서번호가 범위안에 있어야 하는 값이다.) //참조키
CREATE TABLE emp05(
empno NUMBER PRIMARY KEY,
ename VARCHAR2(20) NOT NULL,
job VARCHAR2(20),
deptno NUMBER REFERENCES departments(department_id)
)
INSERT INTO emp05 VALUES(100, 'park', 'IT', 30000); //참조하는 부모키에서 이런 레퍼런스값을 찾을 수 없다.
**테이블레벨 방식 -> 제약조건 이름을 명시
CREATE TABLE emp06(
empno NUMBER,
ename VARCHAR2(20) NOT NULL,
job VARCHAR2(20),
deptno NUMBER,
CONSTRAINT emp06_empno_pk PRIMARY KEY(empno),
CONSTRAINT emp06_deptno_fk
FOREIGN KEY(deptno)
REFERENCES departments(department_id)
)
**테이블 수정 방식 //테이블 추가 후 -> 제약방식 추가 -> 이 방식으로 짜십시오.
CREATE TABLE emp07(
empno NUMBER,
ename VARCHAR2(20) NOT NULL,
job VARCHAR2(20),
deptno NUMBER
)
ALTER TABLE emp07
ADD CONSTRAINT emp07_empno_pk PRIMARY KEY(empno);
ALTER TABLE emp07
ADD CONSTRAINT emp07_deptno_fk
FOREIGN KEY(deptno)
REFERENCES departments(department_id); //레퍼런스값 참조
*CHECK 제약조건(의도된 데이터만 입력 받기 위해)
CREATE TABLE emp08(
empno NUMBER,
ename VARCHAR2(20) NOT NULL,
job VARCHAR2(20),
deptno NUMBER,
gender char(1) CHECK(gender IN('M', 'F'))
)
INSERT INTO emp08 VALUES(100, 'park', 'IT', 30000, 'A');
INSERT INTO emp08 VALUES(100, 'park', 'IT', 30000, 'M');
*DEFAULT 제약조건
CREATE TABLE emp09(
empno NUMBER,
ename VARCHAR2(20) NOT NULL,
job VARCHAR2(20),
deptno NUMBER,
loc VARCHAR2(20) DEFAULT 'Seoul'
)
INSERT INTO emp09(empno, ename, job, deptno)
VALUES(100, 'park', 'IT', 30);
*2개 이상 주식별자 설정
CREATE TABLE emp10(
empno NUMBER,
ename VARCHAR2(20) NOT NULL,
job VARCHAR2(20),
deptno NUMBER
)
ALTER TABLE emp10
ADD CONSTRAINT emp07_empno_pk
PRIMARY KEY(empno, ename);
INSERT INTO emp10 VALUES(100, 'park', 'IT', 30);
INSERT INTO emp10 VALUES(100, 'kim', 'IT', 30); //주키가 두개라 상관없음. 두개가 같아야만 중복
*제약조건 삭제
ALTER TABLE 테이블명
DROP CONSTRAINT 제약조건이름
방법3가지(부모의 30번 부서를 삭제하고싶을때)
-
30번 부서의 사람들을 다른 부서로 옮겨서 그 부분을 비워놓는다.
-
제약조건 삭제
-
↓
CREATE TABLE 테이블명
deptno NUMBER REFERENCES 참조테이블(참조컬럼명)
ON DELETE CASCADE
->department테이블에서 특정번호(30번 부서)를 삭제시
emp10에서 30번 부서에 근무하는 사람들도 함께 삭제
<과제>
1.테이블생성
2.제약조건생성(테이블 수정방식으로)
3.데이터 입력, 삭제를 통해 제약조건이 잘 형성되었나 점검
1. 회원 정보를 저장하는 테이블을 MEMBER란 이름으로 생성한다.
컬럼명 자료형 크기 유일키 NULL허용 키 비고
ID VARCHAR2 20 Y N PK 회원ID
NAME VARCHAR2 20 N N 이름
REGNO VARCHAR2 13 Y N 주민번호
HP VARCHAR2 13 Y Y 핸드폰번호
ADDRESS VARCHAR2 100 N Y 주소
2.도서정보를 저장하는 테이블 BOOK이라는 이름을 생성한다.
컬럼명 자료형 크기 유일키 NULL허용 키 비고
CODE NUMBER 4 Y N PK 제품코드
TITLE VARCHAR2 50 N N 도서명
COUNT NUMBER 6 N Y 수량
PRICE NUMBER 10 N Y 정가
PUBLISH VARCHAR2 50 N Y 출판사
3. 회원이 책을 주문하였을 때 이에 대한 정보를 저장하는 테이블
이름은 ORDER2로한다.
컬럼명 자료형 크기 유일키 NULL허용 키 비고
NO VARCHAR2 10 Y N PK 주문번호
ID VARCHAR2 20 N N FK 회원ID
CODE NUMBER 4 N N FK 제품번호
COUNT NUMBER 6 N Y 주문건수
DR_DATE DATE N Y 주문일자
--1
CREATE TABLE MEMBER(
ID VARCHAR2(20),
NAME VARCHAR2(20),
REGNO VARCHAR2(13),
HP VARCHAR2(13),
ADDRESS VARCHAR2(100)
);
ALTER TABLE MEMBER
ADD CONSTRAINT member_id_pk PRIMARY KEY(ID);
ALTER TABLE MEMBER
MODIFY NAME CONSTRAINT member_name NOT NULL;
ALTER TABLE MEMBER
ADD CONSTRAINT member_regno UNIQUE(REGNO);
ALTER TABLE MEMBER
ADD CONSTRAINT member_hp UNIQUE(HP);
--2
CREATE TABLE BOOK(
CODE NUMBER(4),
TITLE VARCHAR2(50),
COUNT NUMBER(6),
PRICE NUMBER(10),
PUBLISH VARCHAR2(50)
);
ALTER TABLE BOOK
ADD CONSTRAINT book_code_pk PRIMARY KEY(CODE);
ALTER TABLE BOOK
MODIFY TITLE CONSTRAINT book_title NOT NULL;
--3
CREATE TABLE ORDER2(
NO VARCHAR2(10),
ID VARCHAR2(20),
CODE NUMBER(4),
COUNT NUMBER(6),
DR_DATE DATE
);
ALTER TABLE ORDER2
ADD CONSTRAINT order2_no_pk PRIMARY KEY(NO);
ALTER TABLE ORDER2
ADD CONSTRAINT order2_id_fk
FOREIGN KEY(ID)
REFERENCES MEMBER(ID);
ALTER TABLE ORDER2
ADD CONSTRAINT order2_code_fk
FOREIGN KEY(CODE)
REFERENCES BOOK(CODE);
'FULLSTACK > DB' 카테고리의 다른 글
| DB 6차시 - 제어문(조건문), 예외처리, 커서, 프로시저, 함수 (0) | 2020.11.13 |
|---|---|
| DB 5차시 - 인덱스, 뷰, 시퀀스, PL/SQL (0) | 2020.11.13 |
| DB 4차시 - 서브쿼리문 (0) | 2020.11.13 |
| DB 3차시 - 조인(SELF, OUTER) (0) | 2020.11.13 |
| DB 1차시 - DB개념, 연산자 (0) | 2020.11.13 |